11422. Кратчайшая
подпоследовательность
Вам задана последовательность
ДНК, состоящая из символов A, C, G и T.
Найдите кратчайшую
последовательность ДНК, которая не является подпоследовательностью исходной
последовательности.
Вход. Одна строка содержит последовательность
ДНК с n (1 ≤ n ≤ 106) символами.
Выход. Выведите самую короткую последовательность
ДНК, не являющуюся подпоследовательностью исходной последовательности. Если
решений несколько, то выведите любое из них.
|
Пример
входа |
Пример
выхода |
|
ACGTACGT |
AAA |
РЕШЕНИЕ
структуры
данных – set
Анализ алгоритма
Давайте предположим, что входная
последовательность не содержит какой-нибудь одной буквы. Тогда строка из этой
одной буквы будет ответом. Например, для входной строки “AGTTAGAT” ответом будет “C”.
Пусть входная
строка s[0 ..
n – 1] содержит все 4 буквы, однако последняя ее буква sn –
1 встречается в строке только один раз. Тогда ответом будет строка,
содержащая sn
– 1 и любую вторую букву из множества {A, C, G, T}. Например, для входной строки “AGTATAC” ответом будет “CA”.
Пусть k – такое наибольшее
число, что входную строку s можно разбить на k подстрок так, что каждая подстрока содержит
все четыре буквы. Такое разбиение совершим жадным методом, так что последняя
буква каждой подстроки будет входить в подстроку только один раз. Найдем самый
короткий префикс, для которого это имеет место. Часть строки, которая не входит
в префикс, назовем суффиксом. Пусть, например, k = 2, и рассмотрим
строку
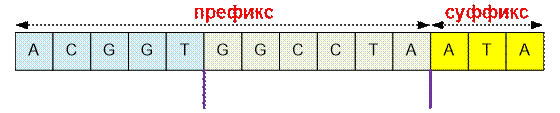
В результирующую
строку следует внести последнюю букву каждой подстроки и любую из букв, которой
нет в суффиксе. Если суффикс пустой, то можно выбрать любую букву. Ответом для
приведенной строки будет “TAC” или “TAG”.
Пример
Разобъем входную
строку на подстроки.
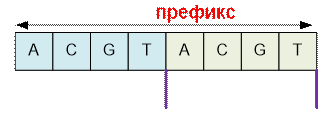
Суффикса в ней
нет (суффикс пустой). Ответом будет
строка, содержащая последние буквы подстрок плюс любая буква, которой нет в
суффиксе. Например, в качестве ответа можно выбрать “TTA”.
Реализация алгоритма
Читаем входную строку s.
cin >> s;
Обрабатываем посимвольно входную строку.
for (i = 0; i < s.size(); i++)
{
Заносим текущий символ s[i] во множество st.
st.insert(s[i]);
Как только множество будет содержать 4 буквы, это означает что s[i] является последней
буквой очередной подстроки, содержащей все 4 буквы.
if
(st.size() == 4)
{
Включаем в результирующую строку res символ s[i] и чистим множество st.
res += s[i];
st.clear();
}
}
Множество st содержит буквы
суффикса. Ищем букву, которой нет в суффиксе и присоединяем ее к res.
for (char i :
"ACGT")
{
if
(st.count(i) == 0)
{
res += i;
break;
}
}
Выводим ответ.
cout
<< res << endl;