4859. Скучная лекция
Леша сидел на лекции. Ему
было невероятно скучно. Голос лектора казался таким далеким и незаметным...
Чтобы окончательно не
уснуть, он взял листок и написал на нем свое любимое слово. Чуть ниже он
повторил свое любимое слово, без первой буквы. Еще ниже он снова написал свое
любимое слово, но в этот раз без двух первых и последней буквы.
Тут ему пришла в голову
мысль – времени до конца лекции все равно еще очень много, почему бы не продолжить
выписывать всеми возможными способами это слово без какой-то части с начала и
какой-то части с конца?
После лекции Леша рассказал
Максу, как замечательно он скоротал время. Максу стало интересно посчитать,
сколько букв каждого вида встречается у Леши в листочке. Но к сожалению, сам
листочек куда-то запропастился.
Макс хорошо знает любимое
слово Леши, а еще у него не так много свободного времени, как у его друга, так
что помогите ему быстро восстановить, сколько раз Леше пришлось выписать каждую
букву.
Вход.
Одна строка, состоящая из строчных латинских букв – любимое слово Леши. Длина строки
лежит в пределах от 5 до 105 символов.
Выход.
Для каждой буквы на листочке Леши, выведите ее, а затем через двоеточие и
пробел сколько раз она встретилась в выписанных Лешей словах (как показано в примерах). Буквы должны следовать в алфавитном порядке. Буквы, не встречающиеся
на листочке, выводить не нужно.
|
Пример входа 1 |
Пример выхода 1 |
|
hello |
e: 8 h: 5 l: 17 o: 5 |
|
|
|
|
Пример входа 2 |
Пример выхода 2 |
|
abacaba |
a: 44 b: 24 c: 16 |
РЕШЕНИЕ
комбинаторика
Анализ алгоритма
Возьмем слово hello и подсчитаем,
сколько раз в выписанных словах встречается например буква e. После буквы e могут
находиться следующие подстроки (суффиксы): Ø (пустая подстрока), l, ll,
llo (4 подстроки). Перед буквой e могут
находиться подстроки (префиксы) Ø, h
(2 подстроки). Соединив любой префикс с любым суффиксом (и использовав один
раз букву e), мы получим все возможные слова,
выписанные Лешей.
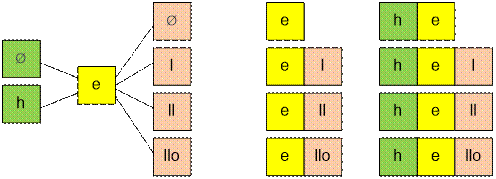
Буква e будет
выписана 2 * 4 = 8 раз.
Для каждой буквы
следует подсчитать, сколько подстрок (включая пустую) может находиться до нее (пусть
будет a подстрок), и сколько
подстрок (включая пустую) может находиться после нее (пусть будет b подстрок). Тогда эта буква
во всех выписанных словах будет встречаться a *
b раз.
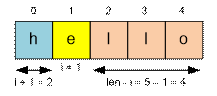
Пусть s – входная строка,
нумерация позиций начинается с нуля. Пусть len – длина строки.
Тогда перед буквой s[i] может находиться
(i + 1) подстрока. После буквы s[i] может
находиться (len – i) подстрок. Всего имеется (i
+ 1) * (len
– i) слов, содержищих
букву s[i].
Реализация алгоритма
Входную строку храним в массиве s.
Количество каждой буквы в выписанных словах подсчитываем в массиве m.
#define MAX 100010
char s[MAX];
long long m[27];
Читаем входную строку s.
gets(s);
memset(m, 0, sizeof(m));
len = strlen(s);
Для каждой буквы s[i] подсчитываем сколько раз она встречается в выписанных Лешей словах.
for (i = 0; i < len; i++)
m[s[i] - 'a'] += 1LL * (i +
1) * (len - i);
Выводим ответ: для каждой буквы печатаем
количество раз, которое оно встречается в словах.
for (i = 0; i < 26; i++)
if (m[i] > 0) printf("%c: %lld\n", i + 'a', m[i]);