6834. Ужасный
список
Наступило время 7-го
Северного Съезда Попкорна, и в этом году у менеджера Яна появилась блестящая
идея. В дополнение к традиционной программе кинопоказа, было решено обустроить
необычную комнату, в которой небольшая группа людей может просмотреть случайный
фильм из большой коллекции, наслаждаясь попкорном и мартини.
Но как оказалось, некоторые
посетители были слишком разочарованы, так как им пришлось смотреть такие фильмы
как Призрак Марса – это заставляло людей рвать на себе волосы в отчаянии и
ужасе.
Чтобы избежать этой проблемы на
следующем съезде, Ян придумал решение, но Вы должны помочь его реализовать.
Когда группа людей входит в необычную комнату, они вводят список фильмов на
компьютере. Это будет ужасный список, состоящий из фильмов, которые
никто из группы не желает смотреть. Конечно же, список варьируется от группы к
группе.
У Вас имеется доступ к базе
сравнений Ужасных Фильмов, которая указывает какие фильмы непосредственно
подобны каким. Считайте, что фильмы, подобные плохим, сами плохие. Определим
индекс Ужасности HI следующим образом:
· HI = 0, если фильм включен в
ужасный список. Это отменяет другие определения.
· HI = q + 1, если худший
непосредственно подобный фильм имеет HI = q,
· HI = +∞, если
фильм не является подобным ужасному.
Вход. Первая строка содержит три
натуральных числа n, h, l (1 ≤ h < n
≤ 1000, 0 ≤ l ≤ 10000), где n – количество
фильмов (представляемых ID от 0 до n – 1), h –
количество фильмов в ужасном списке, а l – количество сходств в базе
данных.
Вторая строка содержит h уникальных
целых xi (0 ≤ xi < n),
указывающих на ID фильмов в ужасном списке.
Каждая из следующих l строк
содержит два целых числа ai, bi (0 ≤ ai
< bi < n), указывающих на то, что фильм
с ID ai подобен фильму с ID bi (и
наоборот).
Выход. Выведите ID наилучшего
фильма коллекции (с наивысшим индексом ужасности). Если таких фильмов
несколько, то выведите фильм с наименьшим ID.
|
Пример
входа 1 |
Пример
выхода 1 |
|
6 3 5 0 5 2 0 1 1 2 4 5 3 5 0 2 |
1 |
|
|
|
|
Пример
входа 2 |
Пример
выхода 2 |
|
6 2 3 5 2 0 5 0 1 3 4 |
3 |
РЕШЕНИЕ
поиск в
ширину
Анализ алгоритма
Построим граф из
n вершин. Ребра
графа соединяют подобные ужасные фильмы. Запустим поиск в ширину из нескольких
источников. Источниками будут фильмы, включенные в ужасный список.
Пусть dist – массив кратчайших
расстояний. Изначально положим dist[i] = MAXINT (например можно положить MAXINT = 0x3F3F3F3F), означающее что расстояние от источников до вершины i равно +∞. По окончанию поиска в ширину если dist[i] будет равно MAXINT, это означает
что фильм i не является подобным ужасному.
ID наилучшего фильма коллекции
равно индексу массива dist с наибольшим значением. Если наибольших значений несколько, то выводим
наименьший индекс среди них.
Пример
Рассмотрим
графы, приведенные в условиях.
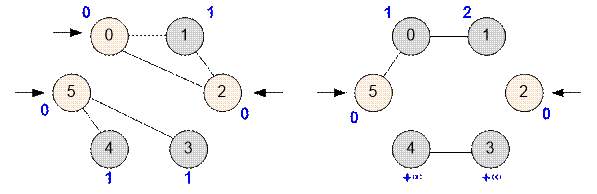
В первом примере
наибольшее расстояние от источников равно 1 и достигается на нескольких
вершинах. Наименьший номер такой вершины равен 1.
Во втором
примере наибольшее расстояние от источников равно +∞ и достигается на вершинах 3 и 4. Искомый наименьший ID фильма равен 3.
Реализация
алгоритма
Объявим рабочие
константы.
#define MAX 1010
#define MAXINT 0x3F3F3F3F
Граф храним в виде матрицы смежности. Объявим массив
кратчайших расстояний dist и очередь q.
int g[MAX][MAX], dist[MAX];
queue<int> q;
Функция bfs совершает поиск в ширину. Очередь q уже заполнена несколькими источниками.
void bfs()
{
while (!q.empty())
{
int v = q.front(); q.pop();
for (int i = 0; i < n; i++)
{
if (g[v][i] == 1 &&
dist[i] == MAXINT)
{
q.push(i);
dist[i] = dist[v] + 1;
}
}
}
}
Основная часть программы. Читаем входные данные.
Инициализируем массивы.
scanf("%d %d %d", &n, &h, &l);
memset(g,
0, sizeof(g));
memset(dist,
0x3F, sizeof(dist));
Читаем h фильмов из ужасного списка. Каждый такой фильм x заносим в очередь q и устанавливаем
расстояние до него равным 0.
for (i = 1; i <= h; i++)
{
scanf("%d", &x);
q.push(x);
dist[x] = 0;
}
Читаем
l неориентированных
ребер графа – пары подобных фильмов.
for (i = 0; i < l; i++)
{
scanf("%d %d", &a, &b);
g[a][b] = g[b][a] = 1;
}
Запускаем поиск в ширину.
bfs();
Ищем индекс ptr массива dist с наибольшим значением. Это и будет ID наилучшего фильма коллекции.
mx = ptr =
0;
for (i = 0; i < n; i++)
if (dist[i] > mx)
{
mx = dist[i];
ptr = i;
}
Выводим ответ.
printf("%d\n", ptr);